Difference between revisions of "Capturing invoice data"
(→Mail) |
|||
| (108 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
| − | + | <div style="font-size: 150%;">'''Location''': "Document loader"</div><br/> | |
| − | |||
| − | + | There are a few possibilities to capture the invoice images: | |
| + | * Via file upload (available from 1Archive version 2.4.119) | ||
| + | * Via mail | ||
| + | * Via webscanning | ||
| − | Invoice images are | + | <br/> |
| + | |||
| + | == Capturing paper invoices by webscanning == | ||
| + | |||
| + | Invoice images are loaded into the system upon arrival through paper webscanning or file import. | ||
<br /> | <br /> | ||
| − | The process of | + | The process of webscanning contains following steps: |
| − | + | # [[Capturing_invoice_data#Batch_preparation_for_paper_invoices|Batch preparation]] | |
| − | + | # [[Capturing_invoice_data#Batch_creation|Batch creation]] | |
| − | + | # [[Capturing_invoice_data#Capturing_the_images_by_scanning|Capturing the images by scanning]] | |
| − | + | # [[Capturing_invoice_data#Separation_validation|Validation of the separation]] | |
| − | + | # [[Capturing_invoice_data#Release_to_recognition_server|Release to the recognition server]] | |
===Batch preparation for paper invoices=== | ===Batch preparation for paper invoices=== | ||
| − | Before scanning the invoices, the scan batches have to be prepared: | + | Before scanning the invoices, the scan batches have to be prepared. Take account of following: |
* Remove all the staples of the invoices | * Remove all the staples of the invoices | ||
| Line 24: | Line 30: | ||
Invoices can be separated by putting a separator sheet between each invoice or by indicating the number of pages per stack of invoices. | Invoices can be separated by putting a separator sheet between each invoice or by indicating the number of pages per stack of invoices. | ||
| − | * You can | + | * The separator sheets can be printed. You can read something more on how to do that [[Capturing_invoice_data#Print_Separation_sheet|here]]. |
| − | * The page indicator can be found in the | + | * The page indicator (to split your documents after a number of pages) can be found in the [[Capturing_invoice_data#Capturing_the_images_by_scanning_.28or_file_import.29|scanning application]]. |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <br/>{{info|Different stacks can be made, depending on the batch fields.}}<br/> | |
| + | {{Note|You always have to divide the invoices depending upon the journal.}}<br/> | ||
| + | '''Best practices for batch creation:''' | ||
* Separate multiple pages and single pages. | * Separate multiple pages and single pages. | ||
| − | ** Scan multiple | + | ** Scan multiple invoice pages with a separator sheet. |
| − | ** Scan single page invoices using the | + | ** Scan single page invoices using the "page indicator". |
* Divide invoices depending on journal. | * Divide invoices depending on journal. | ||
| − | * | + | * Keep invoices and credit notes separated. |
| − | * Stack invoices of same period together | + | * Stack invoices of the same period together. |
| − | * | + | * Restrict your batches to approximately 20-30 documents. |
| − | ===== | + | ===== Screen layout ===== |
| − | + | On the right side of the screen, right below the company selection field, you’ll find the "Actions" menu. Here you can create a batch or print the [[Capturing_invoice_data#Print_Separation_sheet|separation sheet]]. | |
| − | + | The main screen shows a list of different batches available to you. These are available based on: | |
| + | * the user who is logged in. | ||
| + | * the company which is selected. | ||
| + | * availability (you haven't processed them yet). | ||
| − | + | <br/>The list shows you following details of the batches:<br/> | |
| − | The list shows you following details of the batches: | ||
| − | * Batch name: | + | * '''Batch name''': default value is the date of today and the current time. |
| − | * Company: company for which you are scanning | + | ** In case of a mailbatch, default name is "MAIL - date of today and current time". |
| − | * Batch type | + | * '''External UUID''': the uuid of the scanbatch whenever it's processed by an external source |
| + | * '''Creation date''': the date and time on which the batch has been created. | ||
| + | * '''Company''': the company for which you are scanning. | ||
| + | * '''Batch type''': the type of document provided. | ||
** Incoming invoices | ** Incoming invoices | ||
** Outgoing invoices | ** Outgoing invoices | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | In case | + | <br/>{{note|In case the batch is a mailbatch, the type will be ''Incoming invoices'' by default.}}<br/> |
| + | {{info|This can be changed by editing the batch via the [[image:edit.png|link=]] "Edit" button}}<br/> | ||
| + | |||
| + | * '''Reception method''': the method for receiving the documents. Possible values: | ||
| + | ** Webscanning | ||
| + | ** Mail | ||
| + | ** Manual creation | ||
| + | ** XML | ||
| + | * '''Status''': the possible statuses your batch can have. | ||
| + | ** '''New''': the batch has just been created. | ||
| + | ** '''Scanning''': the scanning application is running. | ||
| + | ** '''Received''': the server received the scan batch. | ||
| + | ** '''Ready for transformation''': the batch is ready to be processed by the OCR server. | ||
| + | ** '''Transformation''': the batch is being processed by the OCR server (recognition). | ||
| + | ** '''Import error''': an error occurred while importing the batch into the OCR server. | ||
| + | ** '''Transformation error''': something went wrong during the OCR recognition. | ||
| + | ** '''Finished''': the batch is not visible anymore, documents are ready to be validated in 1Archive | ||
| + | <br/>{{note|In case of import or transformation error, please contact our helpdesk.}}<br/> | ||
| − | + | To the left of the “Actions” menu you can find information on how many scan batch pages are available in the list. | |
Use following icons to move around: | Use following icons to move around: | ||
| − | * [[image:blockFirst.png]] | + | * [[image:blockFirst.png|link=]] '''"First page"''': go to the first page of the list. |
| − | * [[image:blockPrevious.png]] | + | * [[image:blockPrevious.png|link=]] '''"Previous page"''': go to the previous page of the list. |
| − | * [[image:blockNext.png]] | + | * [[image:blockNext.png|link=]] '''"Last page"''': go to the last page of the list. |
| − | * [[image:blockLast.png]] | + | * [[image:blockLast.png|link=]] '''"Next page"''': go to the next page of the list. |
| − | * [[image:blockReload.png]] | + | * [[image:blockReload.png|link=]] '''"Reload"''': is used for refreshing the list. |
| + | |||
| + | {{Note|You can’t continue working with a batch with scanned documents on another computer. Images are locally stored on the computer before sending the batch to the server. So you have to finish your batch on the same computer.}} | ||
| − | + | ===Print separation sheet=== | |
| + | To print the separator sheet choose ''Actions'' then ''Separator sheet.'' | ||
| + | <br/>[[image:separator_sheet.png|link=]]<br /> | ||
| + | <br/>A pdf will appear with the separation sheet. You can print or save it. | ||
===Batch creation=== | ===Batch creation=== | ||
| − | + | <br/>{{warning|Make sure you are working in the company for which you want to scan the invoices. For more info on selecting a company, click [[Working_with_companies#Selecting_a_company|here]].}}<br/> | |
| + | |||
| + | To create a scan batch click on the right side right on ''Actions'' then ''Add scanning batch''. | ||
| + | |||
| + | * Select the batch type (Incoming invoices / Outgoing invoices). | ||
| + | * You can define a batch name, the default value is the current date and time. | ||
| + | * Fill in the batch fields, these fields will contain suggested data based on the default values (which are defined in the settings). | ||
| + | ** Fields available for '''all environments''': | ||
| + | *** Invoice type | ||
| + | *** Journal | ||
| + | ** Fields available for '''EIS''' and '''OIS''' | ||
| + | *** Period | ||
| + | ** Fields available for '''VIS''' | ||
| + | *** Directly to finish | ||
| + | ** Fields available for '''MIS''' | ||
| + | *** Period | ||
| + | *** Directly to finish | ||
| − | + | <br/> | |
| + | {{info|All fields (with exception of ''"Directly to finish"'') will have a proposed value. If you would like to change that value, click the [[image:listPicker.png|link=]] "Lookup list" button to browse the different available options. It's also possible to start typing a value. In that case, a list with possible values will appear.}}<br/> | ||
| − | + | Click the save button to create the batch and click on [[image:scanner.png|link=]] "Scan", located in front of your scan batch, to open the scan application. | |
| + | <br /> | ||
| + | You can use [[image:edit.png|link=]] "Edit scanning batch" to edit the batch fields or [[image:remove.png|link=]] "Remove scanning batch" to delete the batch. | ||
| − | + | ====Directly to finish==== | |
| − | |||
| − | |||
| − | |||
| − | |||
| + | On '''VIS''' and '''MIS''' you have the possibility to set the "Directly to finish" field to "true" when uploading documents. This means that the uploaded documents will be uploaded directly to status '''"Ended"'''. | ||
| + | <br/> | ||
| + | <br/>{{info|This is used for documents which are already available in the accountancy package and need to be imported in 1Archive as well.}} | ||
| + | <br/> | ||
| − | + | ===Capturing the images by scanning=== | |
| + | Put your papers on the scanner and click on [[image:scanner.png|link=]] "Scan" to start scanning. | ||
| + | ::Following screen will pop up. | ||
| + | ::<br />[[image:scanning_popup.png|link=]]<br /> | ||
| − | + | <br/>{{info|All installed scanners will be displayed in this popup screen. If you have a VRS scanner, it is advised to use this device. This is because it's guaranteed to have better scanning results}}<br/> | |
| − | |||
| + | Below the scanner selection list, you have the possibility to check the box for ''"Recto verso"''. This option allows you to scan both sides of a document. | ||
| − | {{ | + | <br/>{{info|Blank pages are deleted when scanning with VRS or when the scan setting ''"Blank page detection"'' is enabled.}}<br/> |
| + | At the bottom of the pop up screen, you can define which settings for separation you would like to use. You have 3 different options to choose from: | ||
| + | * '''Default''': barcode recognition or separator sheet detection is performed during the scanning process. | ||
| + | * '''Split each x pages''': select the number of pages after which you would like to split the document. | ||
| + | <br/>{{note|When scanning one recto verso document, you will have two documents if this setting is set to ''Split each 1 pages''.}} | ||
| + | <br/>{{info|Scanning with the setting ''"Blank page detection" enabled"'': blank pages are deleted during separation. So if you have a batch of all single documents with a blank page on the rear side, you have to put the split number to two.}}<br/> | ||
| + | * '''Ignore separation''': choose this option if you don't want to separate. | ||
| + | <br/>{{note|This option will be the fastest, because no barcode recognition or separator sheet detection is executed.}}<br/> | ||
| + | {{Note|It is advised to use the ''"Blank page detection"'' for webscanning.}}<br/> | ||
| − | : | + | <div style="font-size: 120%">'''Scanning with VRS'''</div> |
| + | Separation is done without taking into account the blank pages. So if you have a batch of all single documents with a blank page on the rear side, you have to put the split number to one. | ||
| + | <br/>If all pages are scanned, you will receive a pop up with the message ''"Out of paper"''. If you want to continue with scanning, put more papers on the scanner and the scanning will continue automatically. If you want to stop, click ''"Cancel"''. | ||
| + | <br/><div style="font-size: 120%">'''Scanning without VRS'''</div> | ||
| + | Repeat the scan steps if you want to scan more pages. | ||
| − | + | ===Edit the webscanning settings=== | |
| + | You can change the settings of the webscanning by clicking the [[image:edit.png|link=]] "Web scanning settings" button inside the webscanning application. | ||
| + | <br/> | ||
| + | <br/>[[image:webscanning_settings.png|link=]] | ||
| + | <br/><div style="font-size: 120%">'''Proxy settings'''</div> | ||
| + | Has to be enabled when you are working with a proxy server. Contact your system administrator for the proxy server details. | ||
| − | + | <br/><div style="font-size: 120%">'''Blank page detection'''</div> | |
| − | <br /> | + | Enable if you want to delete blank pages. You have the possibility to determine the intensity of the blank page detection. |
| − | + | ||
| − | <br /> | + | <br/><div style="font-size: 120%">'''Image optimization'''</div> |
| − | + | Enabled by default. Ensures that the image you are scanning gets optimized. | |
| − | + | ||
| − | + | <br/><div style="font-size: 120%">'''Color conversion'''</div> | |
| + | * '''Black and white (auto)''': default value, automatic conversion to black and white. | ||
| + | * '''Black and white (adaptive)''': another automatic conversion method, but with a different algorithm. | ||
| + | * '''Black and white (treshold)''': allows you to specify the cutoff value for conversion to black and white. | ||
| + | * '''Grayscale (8 bits)''': conversion to grayscale. Improves readability but might reduce recognition rate. | ||
| − | = | + | <br/><div style="font-size: 120%">'''Page setup'''</div> |
| + | '''Page size''': A3, A4 or A5.<br/> | ||
| + | '''Page orientation''': portrait or landscape. | ||
| − | + | <br/><div style="font-size: 120%">'''Logging'''</div> | |
| + | Enable if you want to log what happens during the webscanning. | ||
| + | {{note|Fill in the path to a log file on your hard drive in the text field that becomes editable when enabling this.}} | ||
| − | + | ===Allowed file types=== | |
| − | ** | + | Not every file type can be added in the webscanning application. <br/> |
| − | * | + | <br/> |
| − | + | '''Allowed file types:''' | |
| + | * PDF | ||
| + | * TIF/TIFF | ||
| + | * JPG/JPG | ||
| + | <br/> | ||
| + | '''Not allowed file types:''' | ||
| + | * XML | ||
| + | * XLS/XLSX | ||
| + | * DOC/DOCX | ||
| + | ===Batches in error=== | ||
| + | Whenever a scanbatch enters an error status you're able to import it into the archive anyway by using the [[image:skip-forward.png|link=]] "Skip OCR" button in front of the scanbatch. | ||
| + | <br/>{{warning|As the name of the button already says: this will NOT perform any kind of OCR on your documents. If you use this button, the documents will enter the archive without any recognition performed on them and so no fields will be prefilled.}} | ||
| − | + | == Capturing the images by file import == | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | The webscanning application also has the possibility to import images via file import: | ||
| − | + | # Click [[image:pageAdd.png|link=]] "Add from file" to import PDF/TIFF/JPEG files. | |
| − | + | # In the window that appears, select the files you would like to import. | |
| − | + | #*If you want to select multiple files, use the "Ctrl" button. | |
| − | + | # Blank pages are deleted if configured in the settings. | |
| − | + | # In file import, you can work also with [[Capturing_invoice_data#Print_Separation_sheet|separator sheets]] in order to do separation. | |
| − | + | # If you want to automatically split the imported file(s) in multiple documents, you can select ''Split on import'' and define the number of pages. | |
| − | + | # I you want to move the imported image to a ''Done'' folder, select ''Move to "done" folder when imported'' (a ''Done'' folder will be created in the import folder). | |
| − | ::<br />[[image:split_on_import.png]] | + | ::<br />[[image:split_on_import.png|link=]] |
<br/> | <br/> | ||
| − | == | + | {{Note|When importing files, be aware of following file conditions: |
| + | |||
| + | * Grayscale | ||
| + | * No photo | ||
| + | * 300 dpi | ||
| + | * No secured PDF | ||
| + | |||
| + | }} | ||
| + | |||
| + | == Separation validation == | ||
After scanning you will see in the left pane an overview of all the scanned documents with their different pages (thumbnails). In the right pane you will see the image of the selected page. | After scanning you will see in the left pane an overview of all the scanned documents with their different pages (thumbnails). In the right pane you will see the image of the selected page. | ||
| Line 169: | Line 240: | ||
Following actions can be performed on the scanned pages: | Following actions can be performed on the scanned pages: | ||
| − | * Put pages into a new document by clicking | + | * Put pages into a new document by clicking [[image:documentAdd.png|link=]] "Add a new document". |
| − | * Split a document by | + | * Split a document by clicking [[image:split.png|link=]] "Split the selected document", a new document will be created from this page on. |
| − | * Click [[image:remove.png]] | + | * Click [[image:remove.png|link=]] "Remove selection" to delete the selected document or page. |
| − | * Click [[image:rotateAnticlockwise.png]] | + | * Click [[image:rotateAnticlockwise.png|link=]] "Rotate selected images left" or [[image:rotateClockwise.png|link=]] "Rotate selected images right" to rotate the images. |
| − | * Click [[image:save.png]] | + | * Click [[image:save.png|link=]] "Save and close" to save the scan batch without sending to the OCR server. |
| − | * Click [[image:magnifier.png]] | + | * Click [[image:magnifier.png|link=]] "Zoom factor" to scale the thumbnails. |
* You can drag and drop the selected pages in a document or to another document. | * You can drag and drop the selected pages in a document or to another document. | ||
| − | + | ==Release to recognition server== | |
| + | |||
| + | Click on [[image:send.png|link=]] "Save Send" to save the batch and send it to the OCR server. | ||
| + | |||
| + | ==File upload== | ||
| + | <br/>{{warning|This functionality is only available in Microsoft Edge, Google Chrome, Mozilla Firefox and Safari.}}<br/> | ||
| + | When [[Working_with_companies#Selecting_a_company|selecting a company]], you have an extra connector available:<br/> | ||
| + | <br/>[[image:file_upload.png|link=]]<br/> | ||
| + | |||
| + | <br/>This feature allows you to upload files directly from your computer. When clicking it, a pop-up screen appears:<br/> | ||
| + | <br/>[[image:file_upload_popup.png|link=]]<br/> | ||
| + | <br/> | ||
| + | This screen allows you to define several fields for the upload of your file(s). Available fields: | ||
| + | * '''Batch type''': define the type of your file(s). Possible values are: | ||
| + | ** ''Incoming invoices'' - this will be the default value. | ||
| + | ** ''Outgoing invoices'' | ||
| + | * '''Company''': choose the company for which you would like to upload the file(s). Default value will be the company you selected. | ||
| + | * '''Batch name''': define the name your scanning batch should have. Default value will be the current date and time. | ||
| + | * Fields: | ||
| + | ** '''Invoice type''': choose the type of the file(s) you are uploading. Possible values: | ||
| + | *** ''Invoice (F)'' | ||
| + | *** ''Credit note (C)'' | ||
| + | ** '''Journal''': choose the journal for which the document(s) should be created. Default value will be the default defined in the settings. | ||
| + | ** '''Period''': choose the period for which the document(s) should be created. Default value will be the default defined in the settings. | ||
| + | ** '''Directly to finish''': should the invoice be sent directly to "Ended" or not? (See [[Capturing_invoice_data#Directly_to_finish|"Directly to finish"]] for more information) Possible values: | ||
| + | *** ''True'' | ||
| + | *** ''False'' | ||
| + | * '''Dropzone''': drop the file(s) you need to upload here. This can be done by drag and drop. Just select the file(s) you would like to upload on your computer and drop them in the dropzone. | ||
| + | |||
| + | <br/> | ||
| + | When clicking ''"Save"'', a batch will be created and after all the processing steps are executed, the files will automatically appear in your archive. No extra steps need to be taken. | ||
| + | |||
| + | <br/>{{info|Important to know is that 1 file also equals 1 document in 1Archive. So when uploading multiple files via the file upload, you won't be able to separate those files anymore. For each file, a document in 1Archive will be created.}}<br/> | ||
| + | |||
| + | ==Mail== | ||
| + | |||
| + | <br/>{{warning|You need to have a 1Archive mailbox in order to use the mail possibility}} | ||
| + | <br/><div style="font-size: 130%">[[image:email.png|link=]] '''If you would like to request a mailbox, please contact us via [mailto:onea-support@unifiedpost.com?Subject=New%20mailbox%20request onea-support@unifiedpost.com]'''</div> | ||
| + | |||
| + | <br/>Since 1Archive version 2.4.124, when you request a mailbox for a company, you will receive 5 e-mail addresses that are constructed like this: '''uniquecode.type@environment.oneamail.be'''<br/> | ||
| + | <br/> | ||
| + | |||
| + | The e-mail addresses have some variable elements: | ||
| + | * A unique identifier for your company. | ||
| + | * The type of the documents that will be sent to this address. Possible values are: | ||
| + | ** ''in'': for incoming invoices | ||
| + | ** ''out'': for outgoing invoices | ||
| + | ** ''ein'': for incoming e-invoices | ||
| + | ** ''eout'': for outgoing e-invoices | ||
| + | ** ''scan-in'': for incoming invoices coming from a physical scanner | ||
| + | * The environment you're working in | ||
| + | <br/> | ||
| + | Example: | ||
| + | * 865137851.in@vis.oneamail.be | ||
| + | * 865137851.ein@vis.oneamail.be | ||
| + | * 865137851.out@vis.oneamail.be | ||
| + | * 865137851.eout@vis.oneamail.be | ||
| + | * 865137851.scan-in@vis.oneamail.be | ||
| + | <br/> | ||
| + | |||
| + | The biggest advantage of using these mailboxes is that you '''save time'''. There are some different reasons for that: | ||
| + | * You don't have to manually add these documents in 1Archive | ||
| + | * Most accounting packages have an option to export invoices directly to an e-invoicing format | ||
| + | * The recognition rate of e-invoices is 100% | ||
| + | <br/> | ||
| + | If the accountancy package of your client has a built-in mailing option, they can easily export and e-mail their invoices to you. Which means that they don't have to print out all of their invoices and bring them to you.<br/> | ||
| + | <br/> | ||
| + | <div style="font-size: 130%">'''How does this all work?'''</div> | ||
| + | First of all, you send an e-mail to your 1Archive inbox. This e-mail has to contain the document(s) you want to add as attachments. The ''"Mail download"'' job ensures that your e-mails will be imported into 1Archive. | ||
| + | <br/>{{warning|The maximum size of an e-mail is 20 MB. Anything larger than that will not be accepted into the 1Archive system.}}<br/> | ||
| + | Choose ''"Incoming mail"'' as document type in the ''"Archive"'' screen. | ||
| + | <br/>[[image:incoming_mail.png|link=]]<br/> | ||
| + | <br/>A new line in the list has been created. This line contains some info about your e-mail. | ||
| + | * '''Id''': the ID of the document in 1Archive. | ||
| + | * '''Status''': the status in which the e-mail is. | ||
| + | <br/>{{note|If the status is ''"Finished"'', a batch has been created.}}<br/> | ||
| + | {{note|If the status is ''"No OCR needed"'' or ''"Error"'', an e-mail is sent to the e-mail address defined in your user group. An e-mail can enter these statuses in three different cases: | ||
| + | * There was no attachment provided | ||
| + | * The attachment had an incorrect format | ||
| + | * An error occurred}}<br/> | ||
| + | |||
| + | * '''From''': the mail address from which the mail was sent. | ||
| + | * '''To''': the mail address to which the mail was sent. | ||
| + | * '''CC''': the mail addresses to which the mail was sent as carbon copy. | ||
| + | *'''BCC''': the mail addresses to which the mail was sent as blind carbon copy. | ||
| + | * '''Received date''': the date on which the mail was received. | ||
| + | * '''Subject''': the subject of the mail. | ||
| + | * '''Body''': the body of the mail. | ||
| + | |||
| + | <br/>The document can be viewed via the [[image:magnifier.png|link=]] "View the document" button. See [[Incoming_mail_document_view|"Incoming mail document view"]] for more information about the incoming mail document view.<br/> | ||
| + | After the mail has been processed (and the status of your incoming mail is ''"Finished"''), a mail scanning batch has been created. | ||
| + | |||
| + | <br/>{{note|The process of downloading mails into 1Archive runs every 5 minutes, so it could happen your batch does not appear right away.}}<br/> | ||
| − | + | This batch can be viewed in the ''"Document loader"'' and can be processed the same way as a normal scanning batch. | |
| + | <br/>{{info|See ''"[[Capturing_invoice_data#Capturing the images by scanning|Capturing the images by scanning]]"'' for more info.}}<br/> | ||
| + | {{warning|When there is a mail scanning batch available in status ''"New"'', all newly received e-mails will be added to this scanning batch.}}<br/> | ||
| − | === | + | ===Allowed file types=== |
| + | E-invoices: | ||
| + | * XML with embedded PDF | ||
| + | * XML with a reference to the PDF filename | ||
| − | + | Paper invoices: | |
| + | * PDF | ||
| + | * TIF/TIFF | ||
| + | * JPG/JPEG | ||
| − | + | <br/>{{info|When a not supported file type is sent to a mailbox, the e-mail has no attachment at all or the attachment is password protected, the incoming mail will come in a status ''"No OCR needed"'' and an e-mail will be sent to the dossier manager, informing him that a document could not be processed.}}<br/> | |
| − | <br /> | + | {{warning|When sending an e-mail with a PDF and an Excel file as attachments, a new scanbatch with only the PDF file will be generated.}}<br/> |
| − | + | ||
| + | ===How to consult the original e-mail?=== | ||
| + | # Open the mail document in the ''Incoming mail'' document type. (See ''[[Validating_invoices#Selecting_the_appropriate_document_type|Selecting the appropriate document type]]'' for how to). | ||
| + | # Click the ''Attachments'' tab (See ''[[Incoming_mail_document_view|Incoming mail document view]] for the correct tab). | ||
| + | # Find the attachment with the ''".eml"'' extension and click the [[image:save.png|link=]] "Download attachment" icon. | ||
| + | # The ''".eml"'' file will be downloaded to your system. Check your ''Downloads'' folder for that file and open it with your e-mail application. | ||
| + | |||
| + | ===Marking an error mail as resolved=== | ||
| + | Whenever a mail enters the 1Archive system in status "Error" or "No OCR needed", a button [[image:accepted.png|link=]] "Mark as resolved" is shown. Clicking this button wil update the status of this e-mail to "Resolved", indicating someone already looked at the error. | ||
| + | |||
| + | ===Automatically split documents in an e-mail=== | ||
| + | Version 2019.4 of 1Archive gives you the possibility to automatically split documents coming from an e-mail. When an e-mail enters the system and the PDF document inside it contains multiple invoices separated with a separator sheet (click [[Capturing_invoice_data#Print_separation_sheet|here]] to read about how you download the separator sheet), these will automatically be split whenever you open the webscanning application. | ||
| + | |||
| + | ==E-invoicing== | ||
| + | E-invoices can be uploaded to 1Archive using a scanning connector, or via a configurable mailbox. | ||
| + | |||
| + | ===Scanning connector=== | ||
| + | In the ''Document loader'' screen, there is a connector '''E-invoice upload''' available. | ||
| + | |||
| + | <br/>[[image:E_invoice_connector.png|link=]]<br/> | ||
| + | |||
| + | Via this connector, it's possible to upload e-invoices to 1Archive. When clicking it, a pop-up screen appears: | ||
| + | |||
| + | <br/>[[image:E_invoice_upload.png|link=]]<br/> | ||
| + | |||
| + | Available fields in this screen are: | ||
| + | * '''Batch type''': define the type of the e-invoices. Possible values are: | ||
| + | ** ''Incoming e-invoices'' | ||
| + | ** ''Outgoing e-invoices'' | ||
| + | * '''Company''': choose the company for which you would like to upload the file(s). Default value will be the company you selected. | ||
| + | * '''Batch name''': define the name your scanning batch should have. Default value will be the current date and time. | ||
| + | * '''Dropzone''': drop the e-invoices you want to upload here. This can be done by drag and drop. Just select the file(s) you would like to upload on your computer and drop them in the dropzone. | ||
| + | <br/>{{info|Note that e-invoices can also be uploaded as a ZIP file. You can find all allowed file types on our [[Supported_file_types_for_upload|"Supported file types for upload"]] page.}}<br/> | ||
| + | |||
| + | There are different ways to upload e-invoice files: | ||
| + | * One way is to upload an XML file with an embedded pdf file. | ||
| + | * Another way is to upload both an XML file and a pdf file. In this case, the XML only has a reference to the pdf and does not include it. | ||
| + | |||
| + | Clicking the ''"Save"'' button results in the creation of a scanning batch. | ||
| + | <br/>{{info|Via the [[image:view_ok.png|link=]] "View" button it's possible to see which files are processed.}}<br/> | ||
| + | |||
| + | After the processing of the scanning batch, the file(s) are available in the archive. | ||
| + | |||
| + | <br/>{{warning|[[image:no_mapping_found.jpg|1225px|link=]]<br/> When the scanbatch enters status ''"Error"'' with above message, this means that no [[Appendix:_XML_mapping_GUI|XML mapping]] was provided. In that case, please contact us to provide you with such mapping.}} | ||
| + | |||
| + | ===Mailbox=== | ||
| + | See [[Capturing_invoice_data#Mail|above]] for more information about the processing of e-mails. | ||
| + | |||
| + | <br/>{{warning|If you would like to use the mail functionality for e-invoices, you need a different mailbox than the one for normal invoices.<br/> | ||
| + | You need a mailbox for each document type you wish to receive e-mails for. So if you would like to use the e-mail functionality for incoming invoices, incoming e-invoices and outgoing e-invoices, you need 3 different mailboxes.}}<br/> | ||
Latest revision as of 15:17, 12 October 2021
There are a few possibilities to capture the invoice images:
- Via file upload (available from 1Archive version 2.4.119)
- Via mail
- Via webscanning
Contents
1 Capturing paper invoices by webscanning
Invoice images are loaded into the system upon arrival through paper webscanning or file import.
The process of webscanning contains following steps:
- Batch preparation
- Batch creation
- Capturing the images by scanning
- Validation of the separation
- Release to the recognition server
1.1 Batch preparation for paper invoices
Before scanning the invoices, the scan batches have to be prepared. Take account of following:
- Remove all the staples of the invoices
- No stamps or post-it on the invoices
- Eliminate publicity
Invoices can be separated by putting a separator sheet between each invoice or by indicating the number of pages per stack of invoices.
- The separator sheets can be printed. You can read something more on how to do that here.
- The page indicator (to split your documents after a number of pages) can be found in the scanning application.
| Different stacks can be made, depending on the batch fields. |
| You always have to divide the invoices depending upon the journal. |
Best practices for batch creation:
- Separate multiple pages and single pages.
- Scan multiple invoice pages with a separator sheet.
- Scan single page invoices using the "page indicator".
- Divide invoices depending on journal.
- Keep invoices and credit notes separated.
- Stack invoices of the same period together.
- Restrict your batches to approximately 20-30 documents.
1.1.1 Screen layout
On the right side of the screen, right below the company selection field, you’ll find the "Actions" menu. Here you can create a batch or print the separation sheet.
The main screen shows a list of different batches available to you. These are available based on:
- the user who is logged in.
- the company which is selected.
- availability (you haven't processed them yet).
The list shows you following details of the batches:
- Batch name: default value is the date of today and the current time.
- In case of a mailbatch, default name is "MAIL - date of today and current time".
- External UUID: the uuid of the scanbatch whenever it's processed by an external source
- Creation date: the date and time on which the batch has been created.
- Company: the company for which you are scanning.
- Batch type: the type of document provided.
- Incoming invoices
- Outgoing invoices
| In case the batch is a mailbatch, the type will be Incoming invoices by default. |
| This can be changed by editing the batch via the |
- Reception method: the method for receiving the documents. Possible values:
- Webscanning
- Manual creation
- XML
- Status: the possible statuses your batch can have.
- New: the batch has just been created.
- Scanning: the scanning application is running.
- Received: the server received the scan batch.
- Ready for transformation: the batch is ready to be processed by the OCR server.
- Transformation: the batch is being processed by the OCR server (recognition).
- Import error: an error occurred while importing the batch into the OCR server.
- Transformation error: something went wrong during the OCR recognition.
- Finished: the batch is not visible anymore, documents are ready to be validated in 1Archive
| In case of import or transformation error, please contact our helpdesk. |
To the left of the “Actions” menu you can find information on how many scan batch pages are available in the list.
Use following icons to move around:
-
 "First page": go to the first page of the list.
"First page": go to the first page of the list. -
 "Previous page": go to the previous page of the list.
"Previous page": go to the previous page of the list. -
 "Last page": go to the last page of the list.
"Last page": go to the last page of the list. -
 "Next page": go to the next page of the list.
"Next page": go to the next page of the list. -
 "Reload": is used for refreshing the list.
"Reload": is used for refreshing the list.
| You can’t continue working with a batch with scanned documents on another computer. Images are locally stored on the computer before sending the batch to the server. So you have to finish your batch on the same computer. |
1.2 Print separation sheet
To print the separator sheet choose Actions then Separator sheet.
A pdf will appear with the separation sheet. You can print or save it.
1.3 Batch creation
| Make sure you are working in the company for which you want to scan the invoices. For more info on selecting a company, click here. |
To create a scan batch click on the right side right on Actions then Add scanning batch.
- Select the batch type (Incoming invoices / Outgoing invoices).
- You can define a batch name, the default value is the current date and time.
- Fill in the batch fields, these fields will contain suggested data based on the default values (which are defined in the settings).
- Fields available for all environments:
- Invoice type
- Journal
- Fields available for EIS and OIS
- Period
- Fields available for VIS
- Directly to finish
- Fields available for MIS
- Period
- Directly to finish
- Fields available for all environments:
| All fields (with exception of "Directly to finish") will have a proposed value. If you would like to change that value, click the |
Click the save button to create the batch and click on ![]() "Scan", located in front of your scan batch, to open the scan application.
"Scan", located in front of your scan batch, to open the scan application.
You can use ![]() "Edit scanning batch" to edit the batch fields or
"Edit scanning batch" to edit the batch fields or ![]() "Remove scanning batch" to delete the batch.
"Remove scanning batch" to delete the batch.
1.3.1 Directly to finish
On VIS and MIS you have the possibility to set the "Directly to finish" field to "true" when uploading documents. This means that the uploaded documents will be uploaded directly to status "Ended".
| This is used for documents which are already available in the accountancy package and need to be imported in 1Archive as well. |
1.4 Capturing the images by scanning
Put your papers on the scanner and click on ![]() "Scan" to start scanning.
"Scan" to start scanning.
- Following screen will pop up.
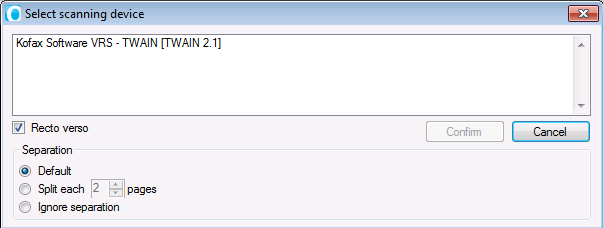
| All installed scanners will be displayed in this popup screen. If you have a VRS scanner, it is advised to use this device. This is because it's guaranteed to have better scanning results |
Below the scanner selection list, you have the possibility to check the box for "Recto verso". This option allows you to scan both sides of a document.
| Blank pages are deleted when scanning with VRS or when the scan setting "Blank page detection" is enabled. |
At the bottom of the pop up screen, you can define which settings for separation you would like to use. You have 3 different options to choose from:
- Default: barcode recognition or separator sheet detection is performed during the scanning process.
- Split each x pages: select the number of pages after which you would like to split the document.
| When scanning one recto verso document, you will have two documents if this setting is set to Split each 1 pages. |
| Scanning with the setting "Blank page detection" enabled": blank pages are deleted during separation. So if you have a batch of all single documents with a blank page on the rear side, you have to put the split number to two. |
- Ignore separation: choose this option if you don't want to separate.
| This option will be the fastest, because no barcode recognition or separator sheet detection is executed. |
| It is advised to use the "Blank page detection" for webscanning. |
Separation is done without taking into account the blank pages. So if you have a batch of all single documents with a blank page on the rear side, you have to put the split number to one.
If all pages are scanned, you will receive a pop up with the message "Out of paper". If you want to continue with scanning, put more papers on the scanner and the scanning will continue automatically. If you want to stop, click "Cancel".
Repeat the scan steps if you want to scan more pages.
1.5 Edit the webscanning settings
You can change the settings of the webscanning by clicking the ![]() "Web scanning settings" button inside the webscanning application.
"Web scanning settings" button inside the webscanning application.
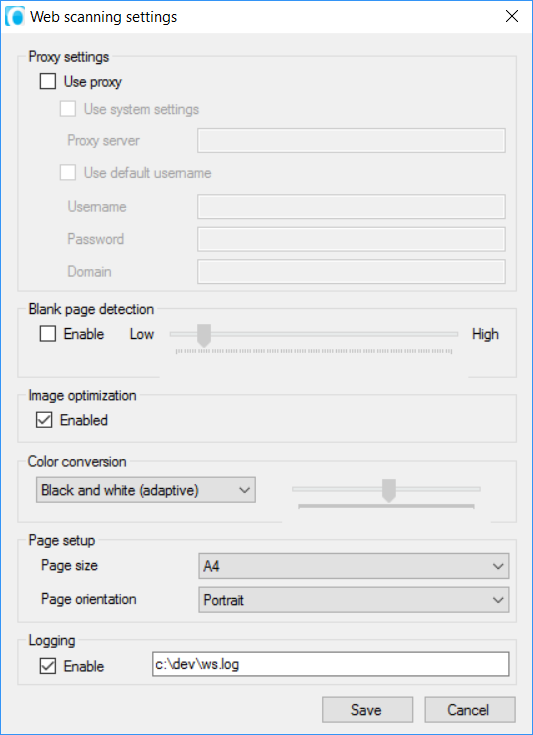
Has to be enabled when you are working with a proxy server. Contact your system administrator for the proxy server details.
Enable if you want to delete blank pages. You have the possibility to determine the intensity of the blank page detection.
Enabled by default. Ensures that the image you are scanning gets optimized.
- Black and white (auto): default value, automatic conversion to black and white.
- Black and white (adaptive): another automatic conversion method, but with a different algorithm.
- Black and white (treshold): allows you to specify the cutoff value for conversion to black and white.
- Grayscale (8 bits): conversion to grayscale. Improves readability but might reduce recognition rate.
Page size: A3, A4 or A5.
Page orientation: portrait or landscape.
Enable if you want to log what happens during the webscanning.
| Fill in the path to a log file on your hard drive in the text field that becomes editable when enabling this. |
1.6 Allowed file types
Not every file type can be added in the webscanning application.
Allowed file types:
- TIF/TIFF
- JPG/JPG
Not allowed file types:
- XML
- XLS/XLSX
- DOC/DOCX
1.7 Batches in error
Whenever a scanbatch enters an error status you're able to import it into the archive anyway by using the ![]() "Skip OCR" button in front of the scanbatch.
"Skip OCR" button in front of the scanbatch.
| As the name of the button already says: this will NOT perform any kind of OCR on your documents. If you use this button, the documents will enter the archive without any recognition performed on them and so no fields will be prefilled. |
2 Capturing the images by file import
The webscanning application also has the possibility to import images via file import:
- Click
 "Add from file" to import PDF/TIFF/JPEG files.
"Add from file" to import PDF/TIFF/JPEG files. - In the window that appears, select the files you would like to import.
- If you want to select multiple files, use the "Ctrl" button.
- Blank pages are deleted if configured in the settings.
- In file import, you can work also with separator sheets in order to do separation.
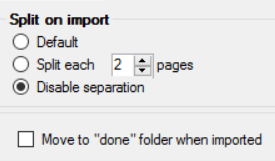
- If you want to automatically split the imported file(s) in multiple documents, you can select Split on import and define the number of pages.
- I you want to move the imported image to a Done folder, select Move to "done" folder when imported (a Done folder will be created in the import folder).
When importing files, be aware of following file conditions:
|
3 Separation validation
After scanning you will see in the left pane an overview of all the scanned documents with their different pages (thumbnails). In the right pane you will see the image of the selected page.
Following actions can be performed on the scanned pages:
- Put pages into a new document by clicking
 "Add a new document".
"Add a new document". - Split a document by clicking
 "Split the selected document", a new document will be created from this page on.
"Split the selected document", a new document will be created from this page on. - Click
 "Remove selection" to delete the selected document or page.
"Remove selection" to delete the selected document or page. - Click
 "Rotate selected images left" or
"Rotate selected images left" or  "Rotate selected images right" to rotate the images.
"Rotate selected images right" to rotate the images. - Click
 "Save and close" to save the scan batch without sending to the OCR server.
"Save and close" to save the scan batch without sending to the OCR server. - Click
 "Zoom factor" to scale the thumbnails.
"Zoom factor" to scale the thumbnails. - You can drag and drop the selected pages in a document or to another document.
4 Release to recognition server
Click on ![]() "Save Send" to save the batch and send it to the OCR server.
"Save Send" to save the batch and send it to the OCR server.
5 File upload
| This functionality is only available in Microsoft Edge, Google Chrome, Mozilla Firefox and Safari. |
When selecting a company, you have an extra connector available:

This feature allows you to upload files directly from your computer. When clicking it, a pop-up screen appears:
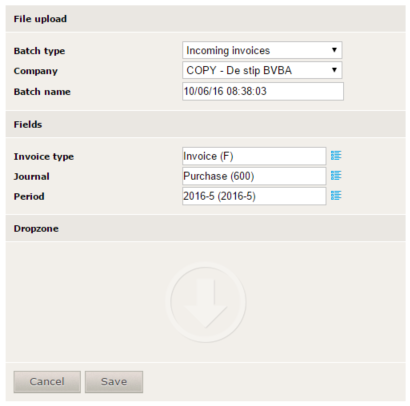
This screen allows you to define several fields for the upload of your file(s). Available fields:
- Batch type: define the type of your file(s). Possible values are:
- Incoming invoices - this will be the default value.
- Outgoing invoices
- Company: choose the company for which you would like to upload the file(s). Default value will be the company you selected.
- Batch name: define the name your scanning batch should have. Default value will be the current date and time.
- Fields:
- Invoice type: choose the type of the file(s) you are uploading. Possible values:
- Invoice (F)
- Credit note (C)
- Journal: choose the journal for which the document(s) should be created. Default value will be the default defined in the settings.
- Period: choose the period for which the document(s) should be created. Default value will be the default defined in the settings.
- Directly to finish: should the invoice be sent directly to "Ended" or not? (See "Directly to finish" for more information) Possible values:
- True
- False
- Invoice type: choose the type of the file(s) you are uploading. Possible values:
- Dropzone: drop the file(s) you need to upload here. This can be done by drag and drop. Just select the file(s) you would like to upload on your computer and drop them in the dropzone.
When clicking "Save", a batch will be created and after all the processing steps are executed, the files will automatically appear in your archive. No extra steps need to be taken.
| Important to know is that 1 file also equals 1 document in 1Archive. So when uploading multiple files via the file upload, you won't be able to separate those files anymore. For each file, a document in 1Archive will be created. |
6 Mail
| You need to have a 1Archive mailbox in order to use the mail possibility |
Since 1Archive version 2.4.124, when you request a mailbox for a company, you will receive 5 e-mail addresses that are constructed like this: uniquecode.type@environment.oneamail.be
The e-mail addresses have some variable elements:
- A unique identifier for your company.
- The type of the documents that will be sent to this address. Possible values are:
- in: for incoming invoices
- out: for outgoing invoices
- ein: for incoming e-invoices
- eout: for outgoing e-invoices
- scan-in: for incoming invoices coming from a physical scanner
- The environment you're working in
Example:
- 865137851.in@vis.oneamail.be
- 865137851.ein@vis.oneamail.be
- 865137851.out@vis.oneamail.be
- 865137851.eout@vis.oneamail.be
- 865137851.scan-in@vis.oneamail.be
The biggest advantage of using these mailboxes is that you save time. There are some different reasons for that:
- You don't have to manually add these documents in 1Archive
- Most accounting packages have an option to export invoices directly to an e-invoicing format
- The recognition rate of e-invoices is 100%
If the accountancy package of your client has a built-in mailing option, they can easily export and e-mail their invoices to you. Which means that they don't have to print out all of their invoices and bring them to you.
First of all, you send an e-mail to your 1Archive inbox. This e-mail has to contain the document(s) you want to add as attachments. The "Mail download" job ensures that your e-mails will be imported into 1Archive.
| The maximum size of an e-mail is 20 MB. Anything larger than that will not be accepted into the 1Archive system. |
Choose "Incoming mail" as document type in the "Archive" screen.
![]()
A new line in the list has been created. This line contains some info about your e-mail.
- Id: the ID of the document in 1Archive.
- Status: the status in which the e-mail is.
| If the status is "Finished", a batch has been created. |
If the status is "No OCR needed" or "Error", an e-mail is sent to the e-mail address defined in your user group. An e-mail can enter these statuses in three different cases:
|
- From: the mail address from which the mail was sent.
- To: the mail address to which the mail was sent.
- CC: the mail addresses to which the mail was sent as carbon copy.
- BCC: the mail addresses to which the mail was sent as blind carbon copy.
- Received date: the date on which the mail was received.
- Subject: the subject of the mail.
- Body: the body of the mail.
The document can be viewed via the ![]() "View the document" button. See "Incoming mail document view" for more information about the incoming mail document view.
"View the document" button. See "Incoming mail document view" for more information about the incoming mail document view.
After the mail has been processed (and the status of your incoming mail is "Finished"), a mail scanning batch has been created.
| The process of downloading mails into 1Archive runs every 5 minutes, so it could happen your batch does not appear right away. |
This batch can be viewed in the "Document loader" and can be processed the same way as a normal scanning batch.
| See "Capturing the images by scanning" for more info. |
| When there is a mail scanning batch available in status "New", all newly received e-mails will be added to this scanning batch. |
6.1 Allowed file types
E-invoices:
- XML with embedded PDF
- XML with a reference to the PDF filename
Paper invoices:
- TIF/TIFF
- JPG/JPEG
| When a not supported file type is sent to a mailbox, the e-mail has no attachment at all or the attachment is password protected, the incoming mail will come in a status "No OCR needed" and an e-mail will be sent to the dossier manager, informing him that a document could not be processed. |
| When sending an e-mail with a PDF and an Excel file as attachments, a new scanbatch with only the PDF file will be generated. |
6.2 How to consult the original e-mail?
- Open the mail document in the Incoming mail document type. (See Selecting the appropriate document type for how to).
- Click the Attachments tab (See Incoming mail document view for the correct tab).
- Find the attachment with the ".eml" extension and click the "Download attachment" icon.
- The ".eml" file will be downloaded to your system. Check your Downloads folder for that file and open it with your e-mail application.
6.3 Marking an error mail as resolved
Whenever a mail enters the 1Archive system in status "Error" or "No OCR needed", a button ![]() "Mark as resolved" is shown. Clicking this button wil update the status of this e-mail to "Resolved", indicating someone already looked at the error.
"Mark as resolved" is shown. Clicking this button wil update the status of this e-mail to "Resolved", indicating someone already looked at the error.
6.4 Automatically split documents in an e-mail
Version 2019.4 of 1Archive gives you the possibility to automatically split documents coming from an e-mail. When an e-mail enters the system and the PDF document inside it contains multiple invoices separated with a separator sheet (click here to read about how you download the separator sheet), these will automatically be split whenever you open the webscanning application.
7 E-invoicing
E-invoices can be uploaded to 1Archive using a scanning connector, or via a configurable mailbox.
7.1 Scanning connector
In the Document loader screen, there is a connector E-invoice upload available.

Via this connector, it's possible to upload e-invoices to 1Archive. When clicking it, a pop-up screen appears:
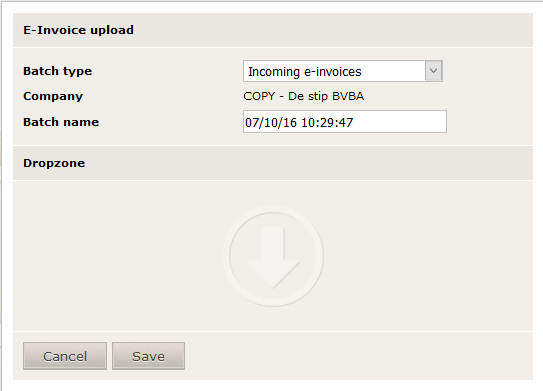
Available fields in this screen are:
- Batch type: define the type of the e-invoices. Possible values are:
- Incoming e-invoices
- Outgoing e-invoices
- Company: choose the company for which you would like to upload the file(s). Default value will be the company you selected.
- Batch name: define the name your scanning batch should have. Default value will be the current date and time.
- Dropzone: drop the e-invoices you want to upload here. This can be done by drag and drop. Just select the file(s) you would like to upload on your computer and drop them in the dropzone.
| Note that e-invoices can also be uploaded as a ZIP file. You can find all allowed file types on our "Supported file types for upload" page. |
There are different ways to upload e-invoice files:
- One way is to upload an XML file with an embedded pdf file.
- Another way is to upload both an XML file and a pdf file. In this case, the XML only has a reference to the pdf and does not include it.
Clicking the "Save" button results in the creation of a scanning batch.
| Via the |
After the processing of the scanning batch, the file(s) are available in the archive.
When the scanbatch enters status "Error" with above message, this means that no XML mapping was provided. In that case, please contact us to provide you with such mapping. |
7.2 Mailbox
See above for more information about the processing of e-mails.
| If you would like to use the mail functionality for e-invoices, you need a different mailbox than the one for normal invoices. You need a mailbox for each document type you wish to receive e-mails for. So if you would like to use the e-mail functionality for incoming invoices, incoming e-invoices and outgoing e-invoices, you need 3 different mailboxes. |